Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
In this Discussion
Guests: Kayla Adams * Sophia Beall * Daisy Bell * Hope Carpenter * Dimitrios Chavouzis * Esha Chekuri * Tucker Craig * Alec Fisher * Abigail Floyd * Thomas Forman * Emily Fuesler * Luke Greenwood * Jose Guaraco * Angelina Gurrola * Chandler Guzman * Max Li * Dede Louis * Caroline Macaulay * Natasha Mandi * Joseph Masters * Madeleine Page * Mahira Raihan * Emily Redler * Samuel Slattery * Lucy Smith * Tim Smith * Danielle Takahashi * Jarman Taylor * Alto Tutar * Savanna Vest * Ariana Wasret * Kristin Wong * Helen Yang * Katherine Yang * Renee Ye * Kris Yuan * Mei Zhang
Code Critique: Mel, FIRESTARTER and Misreading Code

Title: FIRESTARTER
Author: Daniel Hackenberg et al.
Languages: Python, C, x86-64 assembly
Date: 2013-
Git repo: https://github.com/tud-zih-energy/FIRESTARTER
Requirements: Python and a C compiler (I have not confirmed the OSX or Windows versions; the code is native to Linux)
TL;DR: Programmers (and processor architects) usually write with some intent in mind, and the resulting work can be measured against how closely it matches that intent. Once the code escapes into the wild, it can be endlessly repurposed, and the original intents of the authors gradually fade away. In this critique I'll be focusing on two cases where the meaning of repurposed code depends entirely on its externalities: the text of the code becomes divorced from its meaning; the execution of the code is only needed to trigger the external effects. Calling the process "misreading code" doesn't quite capture the sense of mischief involved, but it's close.
The Story of Mel
Eric S. Raymond continues to maintain the collection of hacker lore known as the Jargon File. It's origins go back to 1975, and along with hundreds of definitions of programmer slang of that era it also contains a few longer pieces that distill that culture. The Story of Mel (Ed Nather, 1983) describes the oldest description of code misreading I know of--there are certainly older ones out there--and manages to do so in (unintentional) free verse. It begins:
A recent article devoted to the macho side of programming
made the bald and unvarnished statement:
Real Programmers write in FORTRAN.
Maybe they do now,
in this decadent era of
Lite beer, hand calculators, and “user-friendly” software
but back in the Good Old Days,
when the term “software” sounded funny
and Real Computers were made out of drums and vacuum tubes,
Real Programmers wrote in machine code.
Not FORTRAN. Not RATFOR. Not, even, assembly language.
Machine Code.
Raw, unadorned, inscrutable hexadecimal numbers.
Directly.
The text goes on to describe Mel, a Real Programmer:
Mel never wrote time-delay loops, either,
even when the balky Flexowriter
required a delay between output characters to work right.
He just located instructions on the drum
so each successive one was just past the read head
when it was needed;
the drum had to execute another complete revolution
to find the next instruction.
He coined an unforgettable term for this procedure.
Although “optimum” is an absolute term,
like “unique”, it became common verbal practice
to make it relative:
“not quite optimum” or “less optimum”
or “not very optimum”.
Mel called the maximum time-delay locations
the “most pessimum”.
That's a fun hacker story, but it gains a bit more meaning from a CCS perspective. The drum manufacturer didn't intend for their equipment to be used as an impromptu delay loop. Looking at the text of Mel's code would have revealed instructions carefully splattered across the entire drum, but nothing in the documentation of those instructions would have revealed why that would have been useful. It's only after the externalities are accounted for that the code (and its layout) is revealed as an instance of genius. We're not quite to the point where the code is only triggering externalities; for that, we turn to FIRESTARTER. But first, a quick note each about processor architecture and vector instructions.
A very brief primer on power and processor architecture
Here's what you need to know about the recent evolution of processor architecture. Keeping bits on or off requires very little energy. Switching back and forth takes substantially more energy and generates a lot more heat. Increasing the clock frequency of the processor makes the problem worse, as does increasing the number of bits. Vector instructions use lots of bits (up to 512 per register compared with the usual 32 or 64), and each additional core has its own set of vector registers. Doing lots of vector arithmetic a the highest clock frequency will destroy the processor in a handful of milliseconds. Intel processors (and a few others) monitor how much power is being used and how much heat is being generated. As the processor's limit is reached, the firmware will slow down the processor. As electrical and thermal headroom is restored, the firmware speeds the processor back up. This dithering of clock speeds can happen dozens of times per second and is effectively nondeterministic.
Meet a vector instruction
Say hello to vfmadd231pd, a fused multiply-add vector instruction that, according to Volume 2 of Intel's software development manual, will allow the programmer to:
[m]ultiply packed double-precision floating-point values from [the register] xmm2 and xmm3/mem, add to xmm1 and put result in xmm1 (page 5-120)
From a CCS perspective, we can now say something about a bit of actual code, say....
vfmadd231pd %%zmm5, %%zmm0, %%zmm4
There's even a Wikipedia page devoted to this class of instructions (of course there is), where we learn that fused-multiply-accumulate instructions are useful for speeding up matrix multiplication, neural networks, blah blah blah. In isolation, that's about as far as we can go. So let's look at a bit of context.
FIRESTARTER
Here's a sliver of the hand-crafted assembly that comprises FIRESTARTER, a processor stress test created by another Real Programmer, Daniel Hackenberg at TU-Dresden. The original code is written in Python, which generates C with inline assembly code (as there's no way of convincing a compiler that any pure-C code should result in this). If you're not familar with assembly, no worries---just unfocus your eyes and look for patterns. The more familiar you are with assembly, the stranger this code appears: it looks very much like busywork. The following code begins at line 587 of avx512_functions.c.
".align 64;" /* alignment in bytes */
"_work_loop_skl_xeonep_avx512_1t:"
/****************************************************************************************************
decode 0 decode 1 decode 2 decode 3 */
"vmovapd %%zmm3, 64(%%r9); vfmadd231pd %%zmm4, %%zmm0, %%zmm3; shl $1, %%edi; add %%r14, %%r9; " // RAM store
"vfmadd231pd %%zmm5, %%zmm0, %%zmm4; vfmadd231pd %%zmm6, %%zmm1, %%zmm26; shl $1, %%esi; xor %%rdi, %%r13; " // REG ops only
"vfmadd231pd %%zmm6, %%zmm0, %%zmm5; vbroadcastsd 64(%%rbx), %%zmm5; shl $1, %%edx; add %%r14, %%rbx; " // L1 packed single load
"vfmadd231pd %%zmm7, %%zmm0, %%zmm6; vfmadd231pd %%zmm8, %%zmm1, %%zmm27; shr $1, %%edi; xor %%rdx, %%r13; " // REG ops only
"vfmadd231pd %%zmm8, %%zmm0, %%zmm7; vfmadd231pd 64(%%rbx), %%zmm1, %%zmm7; shr $1, %%esi; add %%r14, %%rbx; " // L1 load
"vfmadd231pd %%zmm9, %%zmm0, %%zmm8; vbroadcastsd 64(%%rbx), %%zmm8; shr $1, %%edx; add %%r14, %%rbx; " // L1 packed single load
"vfmadd231pd %%zmm10, %%zmm0, %%zmm9; vfmadd231pd %%zmm11, %%zmm1, %%zmm28; shl $1, %%edi; xor %%rdx, %%r13; " // REG ops only
"vfmadd231pd %%zmm11, %%zmm0, %%zmm10; vfmadd231pd 64(%%rcx), %%zmm1, %%zmm10; shl $1, %%esi; add %%r14, %%rcx; " // L2 load
"vfmadd231pd %%zmm12, %%zmm0, %%zmm11; vfmadd231pd %%zmm13, %%zmm1, %%zmm29; shl $1, %%edx; xor %%rsi, %%r13; " // REG ops only
"vfmadd231pd %%zmm13, %%zmm0, %%zmm12; vbroadcastsd 64(%%rbx), %%zmm12; shr $1, %%edi;
If you're a processor architect, what jumps out is how busy this processor is. All four instruction decoders are in use, none of the instructions are conflicting with each other (meaning there are no stalls why the processor waits for results to complete or arrive), and.... it's all nonsense.
We're used to thinking of code in terms of symbolic language: each variable and function is a symbol (representation, model, approximation, whatever term you like to use) of some other thing or action. In the code above, FIRESTARTER has removed the symbolic meaning from code. The instructions are being used exclusively to turn actual bits on and off as fast as possible, thus maximizing power and thermal load. The actual mathematical results are overwritten and recalculated again and again---they don't have any meaning as math, they are just a vehicle for flipping bits.
(In terms of speech acts, FIRESTARTER performs a stream of phonetic and phatic acts (noises and words, respectively) which result in a perlocutionary act (the processor heats up) without reaching an illucutionary act (saying something understandable). I'm far from an expert, though, so I'd be happy to hear other opinions.)
Misreading code
What Hackenberg has accomplished is a deliberate, careful misreading of code (more specifically, the instruction set architecture). The intent of the processor architects at Intel was to create specialized instructions for matrix-related mathematics, but the fact that this intent exists does not preclude additional readings. By taking into account the environment in which the intent was realized, Hackeberg can misread these instructions in order to control secondary effects like power consumption and heat generation.
This kind of misreading is most common in security programming (Spectre/Meltdown, Rowhammer, Plundervolt). In each case, the externalities of the running code allow for privilege escalation.
Misreading FIRESTARTER
So far I've described FIRESTARTER as a program that maximizes the power and thermal response of a processor. That was certainly the intent of the authors. Part of the information it reports is how many iterations of its main loop have executed. These are relatively small loops, so the count tends to be quite large. Here is an example of the output from running on my i9-9900K workstation at home. (Note that FIRESTARTER isn't optimized for this processor.)
My machine starts off at 28C with the water pump fans off. Within a couple second after starting the program, the processor temperature has peaked at 99C and the pump fans are spinning up. (The clock frequency will be dropping here.) One those fans are up to speed the processor stays at a reasonable 65C until the run completes. Here's a portion of what FIRESTARTER reports.
performance report:
Thread 0: 118513178 iterations, tsc_delta: 216052936842
Thread 1: 117377514 iterations, tsc_delta: 215995301932
Thread 2: 118972471 iterations, tsc_delta: 215995301370
Thread 3: 116601636 iterations, tsc_delta: 215995301040
Thread 4: 117583482 iterations, tsc_delta: 215995300430
Thread 5: 118341824 iterations, tsc_delta: 215995300118
Thread 6: 116436094 iterations, tsc_delta: 215995298734
Thread 7: 116491650 iterations, tsc_delta: 215995298446
Thread 8: 120026957 iterations, tsc_delta: 215995299742
Thread 9: 119539717 iterations, tsc_delta: 215995297710
Thread 10: 118192628 iterations, tsc_delta: 215995296440
Thread 11: 116883387 iterations, tsc_delta: 215995296062
Thread 12: 117503542 iterations, tsc_delta: 215995294898
Thread 13: 117667925 iterations, tsc_delta: 215995294150
Thread 14: 119323114 iterations, tsc_delta: 215995293560
Thread 15: 116124503 iterations, tsc_delta: 215995291304
total iterations: 1885579622
runtime: 60.02 seconds (216052936842 cycles)
estimated floating point performance: 233.73 GFLOPS
estimated memory bandwidth*: 20.11 GB/s
* this estimate is highly unreliable if --function is used in order to select
a function that is not optimized for your architecture, or if FIRESTARTER is
executed on an unsupported architecture!
Note that the Time Stamp Counter difference (aka tsc_delta) is accurate well within 0.1%; Linux knows how to start and stop execution in the time requested (here, 60 seconds).
But also note that the number of iterations varies quite a bit more than that from thread to thread, from a max of 120026957 to a min of 116124503 iterations completed.
What happens if I run FIRESTARTER 350 times? There is a fair amount of run-to-run variation, but it occurs within a band.
What happens if I run FIRESTARTER 350 on 4,200 ostensibly identical processors (the Quartz supercomputer at LLNL)?
Recall that I mentioned the clock frequency (and thus the number of iterations) depends on the thermal and power load, and that makes deterministic performance more or less impossible. It turns out that the major source of that variation is the variation within the silicon of individual processors. More efficient processors use less power to push bits down their wires, so they can run faster without getting as hot. Less-efficient processors heat up more when running slowly and often can't reach theoretical maximum frequencies at all.
What does that look like? Rather than show you all 4,200 processors, here's the best, worst and median one out of the bunch.
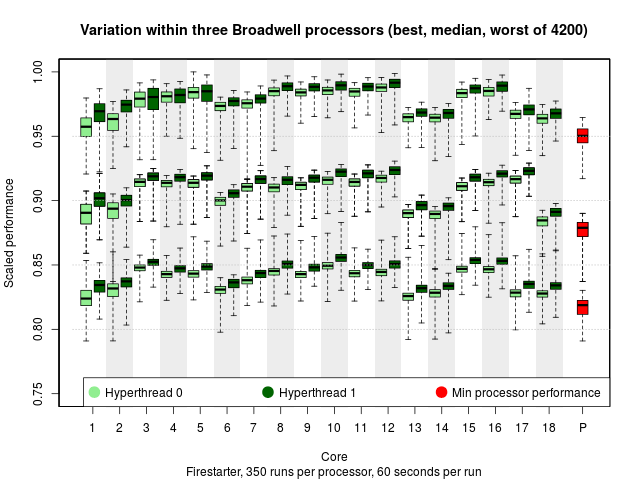
Each box-and-whisker plot shows run-to-run variation (thanks, Linux). There are two hyperthreads per core; there is both core-to-core and hyperthread-to-hyperthread variation (hyperthread 0 is consistently a bit worse than hyperthread 1, and core 12 is consistently better than core 13).
But the processor-to-processor variation dominates. There are the same model and stepping, yet there's an easy 10% difference between the median of the best and the median of the worst processor. (This is known as the "silicon lottery.")
Ok, so what?
Using a bit of undergrad statistics (not shown here), you could run FIRESTARTER for a minute on a random processor and, despite all the variation going on, I'd be able to identify which processor you chose.
In short, I have misread FIRESTARTER to get to the externalities that provide a unique signature for each of 4,200 processors. The FIRESTARTER authors didn't anticipate this. By misreading what they've done, I've gained access to physical information we didn't have before. And that leads to some really gnarly security issues that I'll leave for another time.
Why this matters to CCS
When I was a wee Theater undergrad I had it drilled into my head how the performance consisted of not only actors performing, but the audience and their expectations, the architecture of the theater, subtleties of lighting, sound, costume, gesture, facial expression.... and we have vocabulary and frameworks to discuss how those choices will affect what the audiences takes home. We don't ask whether we can or should misread Shakespeare---that's done as a matter of course. We can do things like stage the first act of Strinberg's Dream Play in the parking lot of an abandoned funeral home in the middle of San Diego where the actors are all mute and their lines have been pre-recorded and are played over loudspeakers (thank you, Sledgehammer Theater). The kind of curiosity and creativity required for that staging feels similar to what's needed for Mel spattering instructions all over his drum memory or Daniel Hackenberg jacking up processor power by executing nonsense fused-multiply-add instructions. We know how to teach those skills to theater students. We're nowhere close to doing that for CS students.
As a computer scientist, I don't have either the vocabulary or frameworks to explain how I go about my misreadings (and I've built my career on them). I would like to give my students and interns an apparatus (or several) that allows them to think about code like their colleagues in the theater department think about performance. I suppose you could say that I want them to read code critically. I'm hoping that CCS can eventually provide that scaffolding.
Questions for Discussion
- You made it this far? You badass!
- Where in the above did your eyes begin to glaze over?
- What are your experiences with deliberate misreading of code?
- How do you teach your students how to be creative, and how would you apply that to teaching CS students?
Comments
There's a well-established vocabulary for talking about this sort of thing, and you used it yourself: "security issue". Security research is the practice of finding holes in the documented abstractions that make up all computer engineering. A hole in an abstraction lets you achieve a result at a lower hardware/software layer that the abstraction was supposed to erase.
Of course a security-minded approach is notoriously hard to teach, so maybe this doesn't help much.
(Speaking of pierced abstractions, surely you've all noticed that in this forum, the "Post Comment" button is labelled in a different font from the "Preview" and "Save Draft" buttons. I don't have the energy to track down the decisions that led to this inharmonious typography -- much less start a separate thread about it -- but the CSS is easy to inspect...)
There is also the category "gross hack," where one feature is misused because it'll have a desired side-effect. These kinds of things have quite the attraction for bright, inquisitive and inventive minds: plus, solving a puzzle by lateral thinking generates good feelings.
The downside is that these kinds of uses are more obscure. "How about we call that 'plan B' and try to fox it properly" is usually the responsible thing to say if the workaround is intended to have any measure of longevity.
However, those responsible alternatives aren't the kinds of things that pass into legend (unlike "changing the value of 4"). It's easy to understand the attraction when a field has a folk mythology that elevates the trickster spirit.
I think there's also a lot to be said for the recreational misuse of software. It keeps us sharp - and as @aplotkin mentions, there are well-paid careers in it these days too.
When I think of "experience with deliberate misreading of code" one analogous set of cultural practices that comes to mind is speedrunning. Many (perhaps most) great speed runs are a collection of "deliberate misreadings" of game systems. The run often focus relentlessly on the difference between what a game says it does... and what it actually does. Some aspects of tool-assisted speedrunning can be a form of advanced professional debugging and/or penetration-testing of a game level design.