Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
In this Discussion
Guests: Kayla Adams * Sophia Beall * Daisy Bell * Hope Carpenter * Dimitrios Chavouzis * Esha Chekuri * Tucker Craig * Alec Fisher * Abigail Floyd * Thomas Forman * Emily Fuesler * Luke Greenwood * Jose Guaraco * Angelina Gurrola * Chandler Guzman * Max Li * Dede Louis * Caroline Macaulay * Natasha Mandi * Joseph Masters * Madeleine Page * Mahira Raihan * Emily Redler * Samuel Slattery * Lucy Smith * Tim Smith * Danielle Takahashi * Jarman Taylor * Alto Tutar * Savanna Vest * Ariana Wasret * Kristin Wong * Helen Yang * Katherine Yang * Renee Ye * Kris Yuan * Mei Zhang
Week 2: Cree#


A simple example of "Hello World" in the first iteration of Cree# with it's graphic output.
Programs in Cree# are told as stories, connecting with the Cree tradition; the graphical output can’t exist without the story that the code is telling. A Cree# program is also a multimedia story. In the above example, we have Raven (the Trickster), a character from Cree folklore who is as well known for his mischievousness as he is known for his role as a teacher and a guide. The program initializes when Raven flies on to the screen and lands on a tree and ends when the Raven flies away. But while sitting on the tree, Raven can perform a number of tasks. In the above example, the Raven says “Hello World” in Cree. But Raven can perform any number of activities, which occur randomly or are controlled through user interaction. It is in the tree-state that the actions of Raven can occur in any order, these activities are only dependant on the storyteller, as each storyteller that tells this story does so with slight modifications and changes in behaviours of Raven in order to emphasize a particular aspect of the story. The Cree# language favours this flexibility in the body of the story so that the generative and dynamic nature of the storyteller’s personality can be reflected in the code, the result is that though a similar (or same) story by different storytellers (i.e. programmers) will be noticeably different in their graphic output, even though they tell the same story.
For an example of what that looks like, here is a longer program in Cree#:

ᒥᔭᐦᑲᓯᑫ᙮
ᒪᒪᐁᐧᔭᐢ ᐃᐧᐦᐅᐃᐧᐣ ᐊᒐᑭᐯᐊᐧᓯᓇᐦᐃᑭᐧᐣ᙮ᑕᓂᓯ᙮
ᐅᓯᐦᒋᑫᐤ ᑳᐦᑳᑭᐤ᙮
ᐅᓯᐦᒋᑫᐤ ᒥᐢᑎᐠ᙮
▬
ᑳᐦᑳᑭᐤ᙮ᐊᐧᐢᑭᑕᐢᑌᐤ᙮ᒥᐢᑎᐠ᙮
ᐃ|| ᑲᐦᑲᑭᐘᐠ᙮ᐊᐧᐢᑭᑕᐢᑌᐤ᙮ᒥᐢᑎᐠ᙮
| ᑳᐦᑳᑭᐤ᙮ᓯᐯᐧᐱᐦᐋᐤ᙮
ᑳᐦᑳᑭᐤ ᐃ᙮ᓯᐯᐧᐱᐦᐋᐤ᙮
ᑳᐦᑳᑭᐘᐠ᙮ᐅᔭᐱᐤ᙮
ᑳᐦᑳᑭᐤ |᙮ᐃᑌᐧ᙮ᑕᓂᓯ ᒥᓯᐁᐧ ᐊᐢᑮᕀ᙮
ᑳᐦᑳᑭᐤ᙮ᓇᓇᒫᐢᑲᒋᐤ᙮
ᑳᐦᑳᑭᐤ᙮ᓯᐯᐧᐱᐦᐋᐤ᙮
ᒥᔭᐦᑲᓯᑫ ᒥᐢᑎᐠ᙮
◯
Because I am still working on the language there is no way to test the above code, so to provide a bit of background to Cree#: its intent is to capture story elements and animate them on the screen. Before writing the code, there must be a series of images or animations created first (like sprites or animated gifs). These are placed in applicable library folders that can then be used in the program by "Creating" them. The verbs used must also be predetermined and unique.
Now as far as the language itself goes the only punctuation in Cree is the full stop "᙮" which is used here to separate statements. The two glyphs used for "start" and "stop" are a horizontal bar "▬", and a circle "◯" respectively. Or in other words "open the circuit" and "close the circuit".
Commands follow basic sentence construction of [noun].[verb], and in some cases [noun].[verb][parameter], and in most cases as long as the program reads in those patterns the order of the instructions is not necessarily relevant. The only exception is smudge, which must be the first line of the program, can be the last line, and can also receive parameter(s) so [smudge] and [smudge][parameter].
Here is a quick run through of the example code:
In this example I start the program with a smudge, then declare two "noun" variables "Raven" and "Tree", open/start the "animation" on line 5. In the first two lines I first add one Raven (ᑳᐦᑳᑭᐤ) to the tree , the next line changes the singular Raven to an array of 5 Ravens (ᐃ|| ᑳᐦᑳᑭᐘᐠ) - note the suffix change from "ᐤ" to "ᐘᐠ", this changes the singular to the plural. And now when I reference the Raven its as an array I can use both singular and plural forms:
Line 8: 1 Raven leaves flying
* because I don't indicate which Raven, one of the array is chosen at random and removed.
Line 9: Raven #3 leaves flying.
* Note that placing a number at the end of the array variable indicates the index - see the end note about Cree numbers
Line 10: using the variable in its plural form ᑳᐦᑳᑭᐘᐠ means apply the action to the entire set
Line 11: Raven #1 speaks "Hello Turtle Island"
Line 12: Raven shivers with cold
Line 13: ᑳᐦᑳᑭᐤ᙮ᓯᐯᐧᐱᐦᐋᐤ᙮ //Raven leaves flying
* this actually only removes 1 raven at random, to remove all I could smudge the singular ᑳᐦᑳᑭᐤ or all ᑳᐦᑳᑭᐘᐠ, or send them all flying ᑳᐦᑳᑭᐘᐠ᙮ᓯᐯᐧᐱᐦᐋᐤ᙮
Line 14: smudge the tree
* the smudge function is used to "cleanse" or reset anything in the program. calling ᙮ᓯᐯᐧᐱᐦᐋᐤ᙮ without any variable will just wipe everything
A note on numbers - the glyphs used for Cree numbers are based on "sticks" with the vertical bar or pipe being 1, 2 pipes is 2, 3 pipes is the same as the syllabic ᐃ, 4 is then ᐃ| - an so on much like roman numerals. There are glyphs for indicating 5, 10, and 20, and higher numbers have differing ways of representing them. An extended example - in many Indigenous numbering systems (not just Cree) the representation of 5 is a hand, and 20 is a person or body, because we are made of 20 digits (10 fingers and toes).
Cree is also a morphemic language, so as long as you know the rules for combining syllables your programming can also be a series of syllable commands strung together. For example there is a prefix "mista" (ᒥᐢᑕ) that can be added to a word to make it a larger version of itself, like ᒥᐢᑕᑳᐦᑳᑭᐤ would be Big Raven, in Cree# this is also a way of adding so - ᒥᐢᑕᑳᐦᑳᑭᐤ (literally big ravens) would actually be a way of increasing my array of 5 Ravens to 6 Ravens. Likewise the suffix "osis" (ᐅᓯᐢ) makes it smaller. ᑳᐦᑳᑭᐤᐅᓯᐢ would therefore remove 1 from the array. And though I have yet to see a need for it, combining the two is still a legal statement so “mista-kahkakiw-osis” or ᒥᐢᑕᑳᐦᑳᑭᐤᐅᓯᐢ, is the same as saying Raven = Raven + 1 - 1.
Comments
I'm interested to hear more about the intended audiences, and how they might begin to use Cree#. Is one audience people who can already read and write Cree, and what would they need to orient them to using Cree writing in this way? Is one audience people who don't already read and write Cree, but who would be learning Cree keywords as part of learning Cree# programming? (This is the way that many non-English speaking students encounter and learn English keywords in programming languages). Are there primary audiences -- ones who the eventual examples, tutorials, and other documentation will target, or who would ideally encounter Cree# in specific cultural contexts?
In this instance Cree# is just a small part of a larger language revitalization project. I am using Cree, because that is my heritage, but as I am also concurrently creating an Indigenous Computing Framework for it to built upon, my basic model should/could be translated to other Indigenous languages.
But just in terms of Cree#, it is more of an umbrella for the Anishinaabe language family, and can easily be modified for Ojibway, Oji-Cree, Saulteaux, Odawa, as well as Inuktitut. And my current "primary" audience I would say are actually grade school students aged 10 to 16 who have a variety of competing languages, with English still being the first language for a majority of them. So Cree# is intended to be a way for today's Indigenous youth to be able to use their ancestral tongue in a context that promotes and encourages their worldview (which is more holistic than Western pedagogies). And hopefully encouraging them to see IT trades in a more favorable light.
As an aside, Indigenous peoples are by far are the most underrepresented group in IT today. A good example of this under-representation can be seen at Google whose employee diversity consists of 0.8% Indigenous (Native American) of their entire organization, with more than half of those being non-tech administrative positions. Some have argued this is due to Western education systems and heavy colonial presence the underscores the IT sector in general.
What a wonderful approach to engaging new generations with language revitalisation. I really look forward to following this project.
I'd love to know more about your experience and process of creating Cree#. Have you found the formal constraints of developing machine-readable Cree# a challenge to conveying the nuances of Cree language? Or has the process enabled your more detailed engagement with the linguistic complexities/intricacies of Cree?
Thank you!
Hi Denise!
the biggest challenges thus far are in terms of plain word construction. There are a number of obstacles with creating a consistent lexer and parser and keeping the actual programming true to the Cree language constructions. For example, modifying syllables of the noun is dependent on animacy. But because animacy is spirit related it does not necessarily mean living or moving. For example, blueberry is inanimate, but raspberry is animate, because raspberry is medicinal and rocks are sacred so rocks are also considered animate. This creates a bit of a challenge when trying to determine the intent of the programmer, when they are referring to "a berry" - because animacy is important to meaning and may not be discernible from the context of the provided instruction(s).
My favorite Cree word to use for examples of morphemic construction is hippopotamus, because it depends on who you ask - each Cree nation has different relationships to the hippo, based on when they were first exposed to the animal. As it is not native to the Americas, it is described similarly, here are a couple examples:
Syllabics: ᑭᐦᒋᑭᐢᐸᑲᓴᑫᐏᒥᐢᑎᑇᒥᒪᐦᑭᑑᓂᓃᔃᐱᑌᐏᐊᑖᒥᐯᑯᐱᒫᑕᑳᐏᑯᐦᑰᐢ
Phonetical: kihci-kispakasakêwi-mistipwâmi-mahkitôni-nîswâpitêwi-atâmipêko-pimâtakâwi-kohkôs
Literal: [great]-[thick-skinned]-[big-thighed]-[big-mouthed]-[two-toothed]-[underwater]-[swimming]-[pig]
and
Syllabics: ᑭᐦᒋᒪᐦᑭᑑᓂᑭᐢᐸᑲᓴᑫᐏᒥᐢᑎᑇᒥᐊᑖᒥᐯᑯᐱᒫᑕᑳᐏᑯᐦᑰᐢ
Phonetical: kihci-mahkitôni-kispakasakêwi-mistipwâmi-atâmipêko-pimâtakâwi-kohkôs
Literal: [great]-[big-mouthed]-[thick-skinned]-[big-butt]-[underwater]-[swimming]-[pig]
Really the only two constants in this case are "Great" and "Pig"; the middle syllables can usually be swapped around and the resulting word will still mean the same thing. So in Cree# you should be able to string "ideas" together in this kind of "lego-block" syllable structure and still have the parser understand and perform the same functions. In my original long example the instructions from lines 7 to 12 are interchangeable and can occur in any order and the parser will still be able to process it as a whole unit (and not just as individual lines).
I'd love to know more about this language revitalization project!
Are you approaching this from a linguistic standpoint? What intrigues me is that, as opposed to the binary code logic usually expressed in coding languages (i.e. Java), you're aiming to focus on storytelling. Construction from words, not numbers. Are you backing that up with some sort of mathematical function?
Using the actual writing of code to enforce culture is not something I've ever thought about before but it makes sense. Do you think most code using the English language as a basis has an overarching affect on the world? English is already the lingua franca. Do you think languages that are built off of English affect how we implement them and the type of code we create? Based off of this and what I already know about speaking different languages and how that changes how we think, I'm inclined to say that yes - it does change not just what we code but how we code.
(Also, the pun Cree# is clever and I love it)
I'm curious to know more about the choice of the trickster figure. I'm definitely a novice in this arena but I've heard the trickster figure described (in reference to Gerald Vizenor's fiction writing, at least) as a sort of response to structures of power which insist on single truths. In which the trickster undermines claims of hierarchal systems of knowledge (such as imperial bureaucracies) by positioning himself as somewhat illegible in those systems. If this is at all accurate, the raven sounds like a particularly interesting "speaker" considering the hierarchal structure of code and the English language norm. Can you speak more to the choice?
tanisi Kalila and Zach!
I'll do my best to answer these questions, starting with Kalila's:
1) Language revitalization is something I actually fell into by accident (or perhaps the Creator led me? LOL). Back when my current research was just an idea of "Why can't I program in Cree?", I was more interested in the domination of English in programming, which led to the realization that it wasn't just English that was the issue, but a large part of programming involves understandings that are not necessarily congruent with cultures that are more ontologically or axiologically focused.
Though I mention language revitalization as a tertiary benefit in my first draft proposals, it was when I presented my project at the American Indigenous Research Association Annual meeting in 2018 that I was approached by a couple Mid-West US band representatives who were super excited about it. They were excited because they knew of a number of bands that have shut off all Western access to their language that stems from previous experiences of academic exploitation (especially by linguists), going so far as to now deny all language exposure to anyone not born in the community (i.e. in the presence of any "outsider" including their own kin, they only speak English if at all possible). What they liked was that my framework allows for language use in the community, capturing stories and teachings as code allows them a way to encode and archive their language, but also allows them to share their culture, as you still get graphical output that can share the stories they want to share, but "hides" the language that runs it keeping it protected. It was at that point I realized that language revitalization and community autonomy was extremely important to these communities and my work will help them in a way pursue these initiatives free of Western influence. That was super exciting to hear, and is now more of a leading concern and not just a happy byproduct.
That in mind, the answer is "no, I am not approaching it from an exclusively linguistic stand point". Though I do make use of linguistic practices, (my PhD co-advisor is Christine Schreyer, who I affectionately refer to as the Mother of Kryptonian, as she created the script and language for the Superman movies), I am careful now to not mention linguistics, because I don't want to alienate those communities who are sensitive to that terminology. But, I do feel there is a definite need to leverage linguistic practices in the underlying language development, it just is not the main point of engagement. I like to say I am programming with culture, not language - or culture is my main computing interface.
2) I'll tell you - creating a programming language where I am trying to avoid number usage altogether is a huge challenge. Computers are inherently mathematical. So performing certain types of tasks like simple counting, keeping track of array sizes, or tracking time - are obstacles I am still working out, I do need to make the environment flexible enough to allow users to adjust things mathematically, the question is how to do this? and is still a development area I haven't quite figured out yet. But at his time I do think these will undoubtedly be operations "behind the scenes". I'm hoping my experience in this working group will give me more ideas of how that might be accomplished. My previous discussions with my cohort Daniel Temkin has already got my wheels turning in this regard, but I am hopeful that I will find even more ideas through this forum.
3) I definitely think that English dominance in computer programming has an overarching affect - Gretchen McCulloch has a great article in Wired magazine from last year "Coding Is for Everyone—as Long as You Speak English" that addresses this question quite nicely.
4) As for the effects of English in code implementation, I see a perpetuation of existing programming paradigms, continual use of English automatically adopts Western and settler/colonial perspectives and practices. Therefore the pedagogical foundations of computer programming are rooted in Western ideas of what coding is, before you even start to learn how to program. For example, I am trying to get the program to be considered as a whole unit not just a collection of linear or progressive commands, which is why morphemic programming is such a challenge, because existing programming frameworks don't support this way of understanding, the theories behind holistic programming paradigms is one step I think to changing this, as is identifying colonial or power-related concepts and practices and removing them in a decolonial computing context.
5) And I totally agree, language is extremely important in what we code AND how we code!
In response to Zach's post
6) The trickster figure (in my tradition is Raven, in others it might be Coyote, Raccoon, Rabbit or just "an animal") But I think in all cases, the role of the trickster is always viewed as teacher and/or benefactor often by way of illustrating what we should NOT do. And, I believe Vizenor understands the complexity of the trickster role, because Indigenous knowledge and thought systems are holistic - the avatars of the trickster are just pieces of a much larger landscape of knowledge that can't be viewed in isolation. I'm not sure I have ever explored the undermining of hierarchical systems - but I like it! I think I will investigate that further! My own belief sees Raven as a knowledge keeper, who at times is a bit too proud for his own good which is why he is always getting in to trouble. Afterall, for all his knowledge he still is not smart enough to ask himself "what could possibly go wrong?" LOL.
My choice of Raven for examples actually is tied to several things:
1) As a knowledge keeper, he is always sharing knowledge, so code = knowledge = code?
2) He is a reminder to watch for pitfalls (in coding)
3) He is also involved with the creation of the world, and by extension the creation of my code.
4) Ironically, Raven also happens to be the Corbett family crest in English heraldic tradition
The use of Cree numerals such as
ᐃ||is a striking aspect of the Cree# language design. Widespread use of Western Arabic numerals across many language contexts is a common feature of language globalization in technical discourse. Whether in hardware interface, software, or programming language design, numbers are often treated as a separate category of symbol with a special relationship to the ontology of computing. This special status is mutually reinforced by many areas of computing culture, from language design. For example, numbers as primitives or distinct numeric types in typed languages) to hardware (for example, the majority of all keyboard layouts have a numeric row as a point of consensus, and that row is often 1234567890. From this point of view, the hegemony of Western Arabic numerals in computing culture may be even greater than the hegemony of Global English.This is even true among Non-English-based_programming_languages, the majority of which use Western Arabic numerals rather than a native numeric systems, or prefer it when it is one of multiple numeral systems in the language. For a variety of examples, UrduScript uses Western Arabic numerals rather than Urdu numerals, תמלילוגו (TamliLogo) uses them rather than Hebrew numerals, کاتی (Kati) uses them rather than Perso-Arabic numerals, and 中蟒 (Chinese Python) uses them rather than Chinese numeral characters.
This commonality makes relatively rare counter-examples such as Cree# even more remarkable. When I looked through other counter-example to see their strategies I selected two as different points of reference. The first is an esoteric programming language. Lingua::Romana::Perligata ("Perl for the XXI-imum Century") implements Perl programming in Latin. Not only are Roman numerals used, but floating point numbers are described with Latin fractions (
unum quartum= 0.25) and indexical references are written Latin language:$unimatrix[1][3][9][7];is writtenseptimum noni tertii primi unimatrixorum("seventh of ninth of third of first of unimatrix"). Notably, this is for input only: the language outputs Western Arabic numerals by default. However, it supports optionally converting output to Roman numerals usingcome/comementum("beautify").Another example is a pragmatic non-English scripting language. চা Script (ChaScript) is a Bengali web script based on ECMAScript. It uses Bengali numerals in both code input and output.[1] One thing informing the native-numeral aspect of চা Script design might be available layouts for Bengali keyboards, many of which likewise include a Bengali number row rather than a Western Arabic number row (or use Bengali numerals as the primary markings on a dual-marked row).
চা Script also has an online editor that provides quick-buttons for common keywords so they needn't be typed. However, perhaps the most interesting thing to me in the context of discussing the Cree# design and goals is the parser. The চা Script parser passes through Western Arabic numerals (and some English keywords), such that it is valid to write চা Script code in various forms of code-mixing and code-switching between চা Script with Bengali keywords and numerals and (English) JavaScript with Western Arabic numerals.
For example, this JavaScript prints numerals from one to ten:
...while this equivalent চা Script prints numerals from ১ to ১০:
...and this valid চা Script uses code-mixing with a combination of চা Script and JavaScript English keywords and Western Arabic Numerals. It also prints from ১ to ১০ (1-10):
I'm curious whether a polyglot that also supports Western Arabic numerals (both ০-৯ and 0-9) is part of Cree# already, or is planned (or not). Does such a thing enhance accessibility and expressivity or instead detract from or compromise the goals of the language design? Thinking about these related issues has also made me wonder about what kinds of keyboards or other input devices / software layers are currently being used while developing Cree# (or other Anishinaabe languages, or beyond)--and what interfaces people might use in the future.
To be clear, চা Script is not a programming languages for indigenous peoples or tribes living in Bangladesh, such as the Chakmas, the Marmas, or the Tripuras, each of whom have their own languages distinct from the dominant Bengali. However it is addressing a linguistic community (Bengali speakers) that is arguably technologically underserved in that language. ↩︎
Thanks for the additional examples Jeremy! These are a couple I do not have in my references yet, so I thank you immensely.
One of the issues with Indigenous numeric systems (in particular North American Indigenous) is that at some point you run into issues with certain number representatives where, for example, anything over 100 is just considered "a lot" or "many" (some Pacific Island communities only go up to 20, so 21 is considered "many" and there is no numbers past this), though some communities may have words for special/sacred concepts or numbers like 1000 or 1M, but there are sometimes limits. Additionally, describing numbers in fractions or decimals is sometimes problematic, because aside from common separations of one half or one quarter there is no way to determine fractional parts, the language just never developed these processes. Although - the Inca Quipu comes to mind... it was an ancient form of accounting that used knotted strings, and was a decimal-based system, so decimal fraction systems did exist pre-contact.
Numbers are a challenging topic. And to your point -
I am not sure if including it Cree# will be an enhancement or a detraction. I think that Western Arabic numbers are, generally speaking, relatively "colonial-free" glyphs used to reference the abstract concept of what a number is, and is probably (as you say) more dominant than English usage, and so may not be that "bad". At this moment, I only have 23 Cree glyphs for number representation (0 through 20, 100, and 1000) So my math capabilities are limited and I do have the ability to use Western Arabic numerals in the language. And I also have to consider other indigenous languages that may adopt this model, and if their primary numerics are Western Arabic then I think I will incorporate both and let the user decide.
How can I get the cree compiler / IDE? This is really blowing my mind. Something about this makes me think about how we could create a programming language to express dreams (dream logic).
Hi Meredith! Ancestral Code/Cree# is still in its infancy, but I hope to release a working beta version of it later this year (I'm shooting for July). I'm sure Mark will be able to facilitate the notification of its release when I have it stable and with adequate documentation
The indispensable Donna Haraway has stuff to read about tricksters, namely the coyote. Isn't the Hacker also a trickster character?
This Cree# language looks like it would be great to program with a stylus or a pen or another instrument like that, rather than a keyboard.
Could you speak a little about the implementation? For starters, the implementation language; and whether its own glyphic limitations have an impact on your code? Are you writing your Cree# implementation in a language derived from European tradition? - and does that make a noticeable difference?
Hi @joncorbett
From the bad advice file...
There are nonlinear programming frameworks, mostly of the constraint-solving variety (AMPL, Prolog), but I don't think they're heading off in a directly you'd find useful.
Those frameworks in turn are written in languages that don't support what you're doing, which in turn are compiled into an instruction set architecture that makes a lot of assumptions that you might not care to make, which in turn runs on a processor whose foremost design principle is backwards compatibility. So....
If you wanted to design your own processor and assembly language to support your higher-level language natively, what would that look like?
Something like Learning FPGAs (O'Reilly) isn't going to be adequate, but the equipment costs are in the tens of dollars (and a few hundred hours). At the end of the process you will have created a toy CPU with its own assembly language with a few dozen lines of code. Getting a processor that's designed around Cree# will get you most of your way towards a PhD in computer engineering.
One of the many reasons this is a terrible idea is that, given a moderately competent framework, you should be able to emulate any other framework (just a lot more slowly). Puzzling out how you want your arithmetic to behave will be hard enough when you have easy-to-use debugging tools and a GUI interface. Trying to work this out by virtually wiring up bits of logic on a PCI board will be much, much harder.... but perhaps interesting to think about.
(Processor designs are just another kind of code susceptible to CCS analysis. There will just be a lot fewer people able to give you feedback.)
Anyway, something to think about, and then avoid doing.
I'm very interested in the morphemic aspect. In nearly all programming languages, an identifier would appear as the same token each time; you wouldn't have a plural version, or a different tense for instance.Cree# carrying meaning within these variations is a challenge to how programming languages are designed. You mentioned that this added a lot of complexity for you, @joncorbett. I'm curious if there's more you can tell us about how this is implemented, but also whether this idea is carried over to variables defined by the user.
This complexity is an interesting bridge between the Cree# conversation and other current working group discussion threads of Inform7, which is natural-language-based programming paradigm. Inform7 has a lot of rules around verbose identifiers and how they are disambiguated by section of the code text, region of space, or period of time -- and "The Big Green Tree" can also be referred to while writing code as "tree", "the tree" ,"the big tree" "the green tree" et cetera with disambiguation that resolves automatically or asks for clarification if there are other trees--big, green, or otherwise.
Absolutely! Writing would be great! One thing I am actually working on is a mechanical keyboard based on the Syllabic Star Chart:
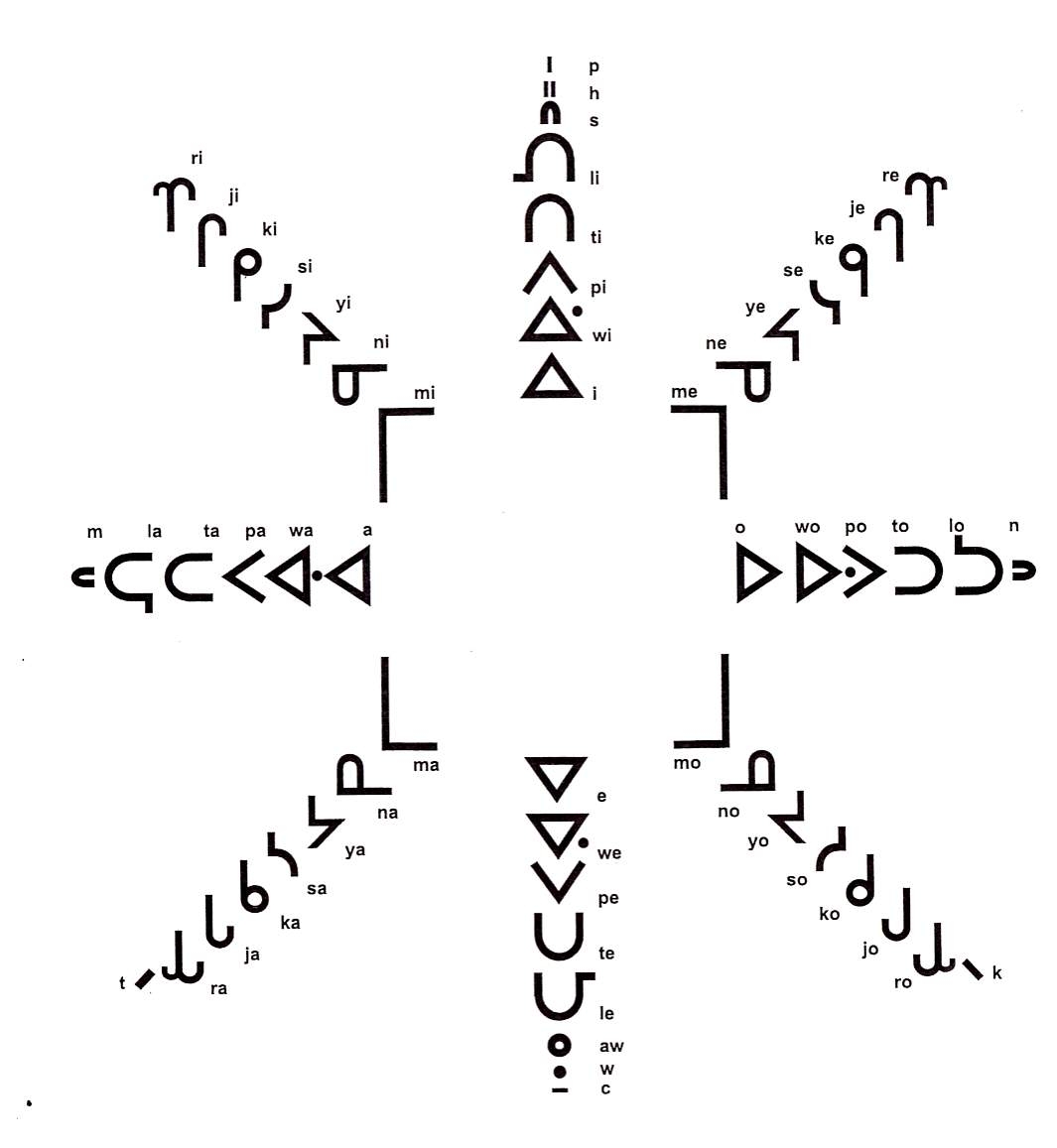
I have a few SketchUp designs on the go for it, just need to get into the maker-space to print the pieces
I am currently using C# and Go for writing the interpreter. C# is a challenge for the unicode aspect - I need to capture the hex values of the glyphs. And Go does have a bit better support for runes using their unicode library. So far it hasn't been too bad, but as this is my first attack at writing a language, and I am new to Go, so I am spending a fair bit of time on these exact issues - of what can I do with the languages that are available.
and thanks for the cautionary tales @barry.rountree. It's funny that you mention
Because this is actually an element of my Indigenous Computing Framework - this idea of computing efficiency is something that (I say) is irrelevant in an Indigenous worldview. Part of this project stems from a work I wrote using Processsing to mimic how I would bead an image, consider these two code snips:
Regular Loop
My chosen code
Though the first example is simpler and more efficient it does not reflect my physical process, and is not in alignment with my axiological or cultural values. So, even though I know my code for the loop I chose is lengthier, the symbolic relationship to having the code render a "continuous" image in a left to right (down) right to left manner is more congruent to an Indigenous model of "looping" and therefore efficiency, verbosity, and even meandering spaghetti code are not concerns, as long as the relationship of the code to culture holds value. I'd even go so far as to say its axiological composition supersedes common notions of linearity and/or syntax. - oh and I definitely don't want to be producing and new hardware except for my keyboard, so no PCI boards for me, I'd like to be able to complete my PhD before man lands on Mars.
@Temkin, with regards to the morphemic nature - this is still very much in design, part of the issue is some of the ways that Cree applies meaning and part of it is the combining of ideas into words that make sense. Because i can have two nouns when concatenated form a respresentation or idea of a new word. A good example is in Anishinaabe (another language similar to Cree), they use the word manidoomin for a bead... but this is actually to morphemes manidoo meaning "spirit" and min meaning "berry". So in a morphemic programming construction placing two nouns together could carry three meanings, and in Cree# this maybe useful for unique interactions, as I mentioned ("mista"ing something) or (another word +"osis") something else can be substitutions for add/increase or subtract/decrease. But this is just a basic concept, I am still learning the nuances of Cree morphemes so I can't think of another decent example at the moment. But suffice to say, that the idea is to take two or more ideas in a single sequence to create a third thing:
I have been toying with an idea that this could be a clever way of performing a switch/case providing the language is constructed properly. Though I am still trying to figure out where my comparative tokens would be in that design.
In an English context, Computational Morphology is not bad in its approach to breaking down morphemic structures of English, and I am still trying to evaluate if it will be useful in building similar extractions for programmatic Cree.
@jeremydouglass I have looked at Inform7 a couple years ago and read through a few sample programs, as it was how I originally thought of making my language - just with images instead of text as the output. I think I will need to revisit this, because if they are using lexemes as in your "The Big Green Tree" example, then this is something worth look into again, because I was not aware they had that capability.
@joncorbett Thank you for your detailed and thoughtful response! I'm sorry for the delay in my reply.
The history of linguistic exploitation is not one I've heard before, so thank you for sharing that. It makes total sense that you'd want to avoid that terminology given that. I was wondering about the point made by some of the people who heard your presentation - sharing culture without sharing the language. Would all the code be hidden? How would you protect it from outsiders looking in and breaking it down ("decoding" it)? It seems like you're caught between trying to make something for Cree speakers but also striving to protect indigenous languages. Technically speaking, how are you planning to resolve this?
Also, a question about the morphemic nature: could coders in Cree# hypothetically create their own words by combining other words? If yes, how would that look in an output?
Thanks again for your reply and sorry for all my questions! I find this work fascinating as language revitalization is something I'm personally interested in.
Thank you @joncorbett ! As someone from a semiotics and critical theory background, it is fascinating to learn more about the possibilities and challenges of coding in Cree#, while also learning about Cree language and culture.
Quick question - Would there be any particular cultural protocols to follow, if I (as a non-indigenous person), wanted to learn cree#? In The Australian context (where I am), there are particular protocols and permissions that one must seek when its comes to referencing First Nations stories, imagery and songs. So I wondered whether the same would apply to cree#, or if broader uptake would be welcomed?
Thank you!
@joncorbett This is wonderful! It's a powerful and important statement to focus on storytelling right from the beginning, rather than simply on calculation and logic. I also find it interesting to hear that Cree# is part of a larger language revitalization project. This gets me thinking about the range of possible digital resources that languages can have (digitized texts or audio, datasets, corpora), and efforts in computational linguistics to create or improve human language technology for low-resources languages. In this context too, I can see how hiding and protecting a language from those who might abuse it for their own gain should be an important feature considered for all language technology. Unfortunately, I've yet to hear computational linguists regularly and carefully consider anything to do with political power, control, and ownership when it comes to developing language technology systems, and for whom. In this sense then, Cree# is leading the way with regards to how this could be approached.
This is kind of the idea I am supporting in a different thread ... that the whole system is built under a series of assumptions not supported by other human languages than English.
I agree here ... the discussion around having Cree# made by making a processor is out of the scope of @joncorbett's PhD. It is nevertheless interesting to entertain the idea of an assembly language following a different understanding of technology.
Yeah :-)
This brings up a conversation of adoption, that I was trying to spark at a different thread. How much of a language / culture you need to adopt before you can build something on top of that. At the end of the day, even if you were to make you own indigenous-risc instruction set, it would be built on top of a technology supporting a different understanding of the world. People would have to adopt a different culture before being able of even making that instruction set.
[I inhale and totally change topic]
I was thinking about compilers in languages that compile their own language. C is written and compiled in C ... how much should Cree# develop before it could be compiled in Cree#? That is maybe a different approach to making these indigenous programming languages and allowing a certain community to entirely take control of it once its core has been developed.
@joncorbett Thank you for sharing this work.
One aspect that I am curious about (after reading the initial post): whether implementing the language (through an interpreter or compiler) made apparent any impedance mismatches with traditional textbook ideas of compiler generation (parsers, lexers, abstract syntax tree, and the like)? What was the most difficult part to implement?
Hey, great post. This script language is fascinating. I was wondering if you could elaborate a little bit more in which aspect do you think Cree# differentiates itself from other programming languages. Thank you!
I am really appreciating the dedication. Inspiring work with the layout and everything")
Sorry Gang! I was at a couple symposiums the past two weeks... great to see such a conversation continued in my absence. Just to catch up:
@gohai
This is definitely the morpheme component that I am still working on... being able to add or change a function by prepending or appending functions to alter the intent of the programmer. For example adding "osis" to "smallerize" something or adding a pluralization to a noun to convert it to an array. The other part is the collective nature of the instruction set. Essentially, the start and end have to be static, but the internal instructions within the block should be able to execute in any order or as described by the programmer (if linear instructions are required). I am still working through these ideas, I hope to find a happy solution that doesn't complicate the coding, and is flexible enough for Indigenous programmers to utilize.
The primary differences occur in the user's cultural perspective. As this is something not usually considered by the programming environment. So things like numbers, loops, conditionals, and variables all need to be considered in a cultural context and usage before creating the programmatic equivalents. In the Olelo Hawaiian version of C# their
ifstatement is a direct reference to rivulet that is branched for growing taro root and then re-enters the river farther downstream. This kind of anecdotal reference assists Indigenous programmers in understanding what they want the system to understand. In many cases Indigenous languages ARE the culture so creating these kind of references are what help the programmer bind the function of the program to a deeper understanding of the knowledge thew system is being asked to represent.I agree Lesia, this is true - that is: in the current political and academic context (from the perspective of the linguist). Unfortunately, there is a very long history of linguists and academics in general capitalizing on the IP of Indigenous community knowledge without reciprocity or acknowledgement of the communities they engaged with (as experienced by in the Indigenous context). This has resulted in a lot of Indigenous communities (especially in North America) being skeptical, suspicious, and resistant to Western research practices in their communities. My hope is that the more platforms that are developed with and for Indigenous people with a culturally-awareness at its base, the more likely this attitude will change.
I certainly hope so!